
In the factories of the future, achieving safe and flexible cooperation between robots and human operators will contribute to enhancing productivity.
The problem of robots performing tasks in collaboration with humans poses the following main challenges: robots must be able to perform tasks in complex, unstructured environments and, at the same time, they must be able to interact naturally with the workers they are collaborating with, while guaranteeing safety all time.
A requirement for natural human-robot collaboration is to endow the robot with the capability to capture, process and understand accurately and robustly human requests.
Using voice and gestures in combination is a natural way for humans to communicate with other humans. By analogy, they can be considered equally relevant to achieve natural communication also between workers and robots.
In such a multimodal communication scenario, the information coming from the different channels can be complementary or redundant, as shown in these examples:
- Complementary: a worker saying “Take this” while pointing at an object.
- Redundant: a worker saying “Stop!” while performing a gesture by raising a hand and showing the palm.
In the first example, the need for different communication channels complementing each other is evident. However, redundancy can also be beneficial in e.g. industrial scenarios in which noise and variable lighting conditions may reduce the robustness of each channel when considered independently.
Our work in the context of the FourByThree project is focused on a semantic approach that supports a multimodal interaction between human workers and industrial robots, in real industrial settings taking advantage of both input channels, voice and gestures. Some examples of this natural interaction could be:
- A human operator asking the robot to complete a certain task.
- A robot asking for clarification when a request is not clear.
- A robot asking the operator to complete some task.
- Once that is done, an operator informing the robot that it can resume its task.
This natural communication facilitates coordination between both actors, enhancing a safe collaboration between robots and workers.
The implemented semantic multimodal interpreter is able to handle voice and gesture-based natural requests from a person and combine both inputs to generate an understandable and reliable command for the industrial robot, facilitating a safe collaboration. For such a semantic interpretation, we have developed four main modules, as it is shown in Figure 1: a Knowledge-Manager module that describes and manages the environment and the actions that are affordable for the robot, using semantic representation technologies; a Voice Interpreter module that, given a voice request, extracts the key elements on the text and translates them into a robot-understandable representation, combining Natural Language Processing and Semantic Web Technologies; a Gesture Interpretation module to resolve pointing gestures and some simple commands like ‘stop’ or ‘resume’; and a Fusion Engine for combining both mechanisms and constructing a complete and reliable robot-commanding mechanism.
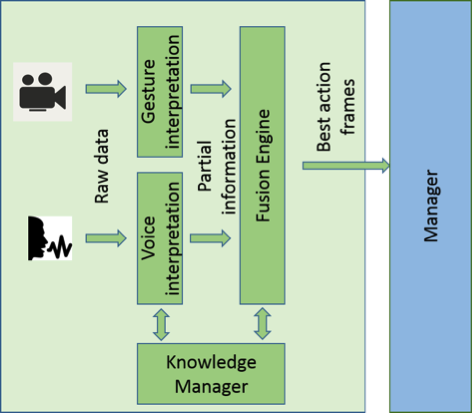 Figure 1: Multimodal semantic interpreter approach architecture.
Figure 1: Multimodal semantic interpreter approach architecture.
The knowledge manager uses an ontology to model the environment and the robot capabilities, as well as the relationships between the elements in the model, which can be understood as implicit rules that a reasoner can exploit to infer new information. Thus, the reasoner can be understood as a rule engine in which human knowledge can be represented as rules or relations. So, through ontologies, we model the industrial scenarios in which robots collaborate with humans. The model includes robot behaviours, actions they can accomplish and the objects they can manipulate/handle. It also considers features and descriptors of these objects.
For each individual action or object, a tag property data is included, listing the most common expression(s) used in natural language to refer to them, including reference to the language used. An automatic semantic extension of those tags exploiting Spanish WordNet [1] is done at initialization time. In this way, we obtain different candidate terms referring to a certain concept, which will be used by the voice interpreter for voice request resolution.
The relations defined within the ontology between the concepts are used by the interpreter for disambiguation at run-time. This ability is very useful for text interpretation because sometimes the same expression can be used to refer to different actions. For instance, people can use the expression remove to request the robot to remove a burr, but also to remove a screw, depending on whether the desired action is deburring or unscrewing, respectively. If the relationships between the actions and the objects over which the actions are performed are known, the text interpretation is more accurate; it will be possible to discern, in each case, to which of both options the expression ‘remove’ corresponds to. Without this kind of knowledge representation, this disambiguation problem is more difficult to solve.
For our current implementation, two industrial contexts of the FourByThree project have been considered: a collaborative assembly task and a collaborative deburring task. The possible tasks the robot can fulfil in both scenarios have been identified and a knowledge base (KB) created, populating the knowledge manager ontology with instances representing those tasks. The knowledge base also includes the elements that take part in both processes, as well as the relationships they have with respect to the tasks. In this way, the semantic representation of the scenarios will be available to support the request interpretation process, not only to infer which is the desired action to perform, but also to ensure that all the necessary information is available and coherent in order to be possible for the robot to perform it.
The voice interpreter, taking as input a human request audio, via Google Speech API gets the request content, processes it by Freeling [2], a Natural Language Processing tool, and extracts the key elements on it based on a pattern recognition strategy. Those key elements are searched at the knowledge base of the corresponding scenario, obtaining the potential tasks the robot can perform and better fits the input request, considering all the information available and exploiting reasoning capabilities of the knowledge manager for inferring the most suitable possibilities, as illustrated in Figure 2.
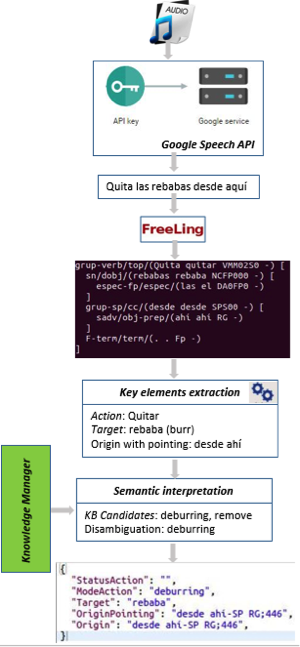 Figure 2: Voice interpreter illustrative execution example.
Figure 2: Voice interpreter illustrative execution example.
The gesture recognition approach is a valuable input in the fusion engine, in which both voice and gesture interpreter outputs are combined to compose the complete request according to the decision strategy summarized in Figure 3.
 Figure 3: Semantic interpreter fusion strategy
Figure 3: Semantic interpreter fusion strategy
At the end of the process, the interpreter is able to send to the robot the proper command according with the operator request, ensuring that the petition is coherent and has all necessary information for its fulfilment by the robot side.
[1] A. González-Agirre, E. Laparra and G. Rigau, “Multilingual central repository version 3.0: upgrading a very large lexical knowledge base,” in GWC 2012 6th International Global Wordnet Conference, 2012. [2] L. Padró y E. Stanilovsky, «Freeling 3.0: Towards wider multilinguality,» de LREC2012, 2012.This guest post has been contributed by Dr. Izaskun Fernández, Researcher of the Intelligent Information Systems unit at IK4-TEKNIKER.